Identify Data Resiliency requirements and policies related to a Nutanix Cluster
Data Resiliency Levels
The following table shows the level of data resiliency (simultaneous failure) provided for the following combinations of replication factor, minimum number of nodes, and minimum number of blocks.
| Replication Factor | Minimum Number of Nodes | Minimum Number of Blocks | Data Resiliency |
| 2 | 3 | 1 | 1 node or 1 disk failure |
| 2 | 3 | 3 (minimum 1 node each) | 1 block or 1 node or 1 disk failure |
| 3 | 5 | 2 | 2 nodes or 2 disk failures |
| 3 | 5 | 5 (minimum 1 node each) | 2 blocks or 2 nodes or 2 disks |
| 3 | 6 | 3 (minimum 2 nodes each) | 1 block or 2 nodes or 2 disks |
| Metro Cluster | 3 nodes at each site | 2 | 1 cluster failure |
Once block fault tolerance conditions are met, the cluster can tolerate a specific number of block failures:
- A replication factor two or replication factor three cluster with three or more blocks can tolerate a maximum failure of one block.
- A replication factor three cluster with five or more blocks can tolerate a maximum failure of two blocks.
Block fault tolerance is one part of a resiliency strategy. It does not remove other constraints such as the availability of disk space and CPU/memory resources in situations where a significant proportion of the infrastructure is unavailable.
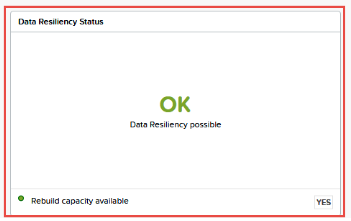
The state of block fault tolerance is available for viewing through the Prism Web Console and Nutanix CLI.
Replication Factor
Replication Factor is the number of times that any piece of data is duplicated on the system. This is directly tied to the Redundancy Factor setting. For example, if you have Redundancy Factor of 2 on the cluster, the only option for Replication Factor on Storage Containers is 2. A Redundancy Factor of 3 on the cluster will allow for a Replication Factor of 2 or 3 for Storage Containers.
| Replication Factor | Requirement | Example |
| Replication factor 2 | There must be at least 3 blocks populated with a specific number of nodes to maintain block fault tolerance. To calculate the number of nodes required to maintain block fault tolerance when the cluster RF=2, you need twice the number of nodes as there are in the block with the most or maximum number of nodes. | There must be at least 5 blocks populated with a specific number of nodes to maintain block fault tolerance. To calculate the number of nodes required to maintain block fault tolerance when the cluster replication factor 3 you need four times the number of nodes as there are in the block with the most or maximum number of nodes |
| Replication factor 3 | If a block contains 4 nodes, you need 16 nodes distributed across the remaining (non-failing) blocks to maintain block fault tolerance for that cluster. X = number of nodes in the block with the most nodes. In this case, 4 nodes in a block. 4X = 16 nodes in the remaining blocks | If a block contains 4 nodes, you need 16 nodes distributed across the remaining (non-failing) blocks to maintain block fault tolerance for that cluster. X = number of nodes in the block with the most nodes. In this case, 4 nodes in a block. 4X = 16 nodes in the remaining blocks. |
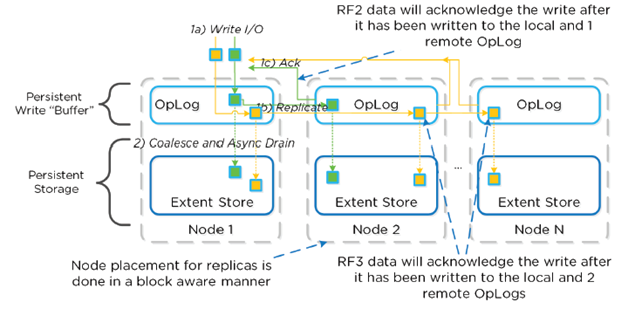
- Replication Factor (RF) + checksum to ensure redundancy/availability
- RF3 = minimum of 5 nodes (metadata will be RF5)
- RF configured via Prism and at Container level
- All nodes participate in OpLog replication = linear performance
- When data is written, checksum is computed and stored as part of its metadata.
- Data then drained to extent store where RF is maintained.
- In case of failure, data is re-replicated amongst all nodes to maintain RF.
- Checksum is computed to ensure validity on every read.
- In case of no match, replica of data will be read and replace non-valid copy.
- Data consistently monitored to ensure integrity
- Stargate’s scrubber operation scans through extent groups to perform checksum validation when disks aren’t heavily utilized
- Nutanix built with idea that hardware will eventually fail
- Systems designed to handle failures in elegant/non-disruptive manner