Determine what capacity optimization method(s) should be used based on a given workload
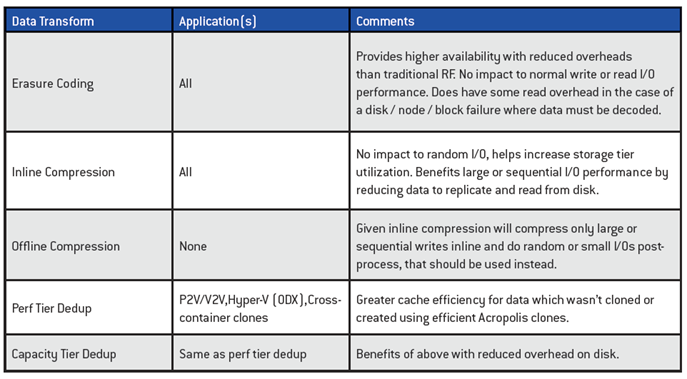
Erasure Coding
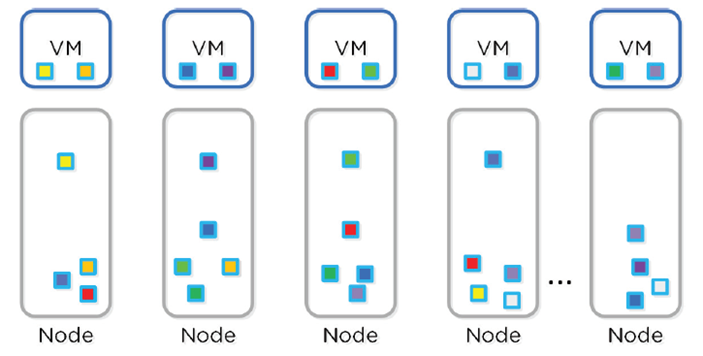
- Similar to RAID where parity is calculated, EC encodes a strip of data blocks on different nodes to calculate parity
- In event of failure, parity used to calculate missing data blocks (decoding)
- Data block is an extent group, and each block is on a different node belonging to a different vDisk
- Configurable based on failures to tolerate data blocks/parity blocks
EC Strip Size:
- Ex. RF2 = N+1
- 3 or 4 data blocks + 1 parity strip = 3/1 or 4/1
- Ex. RF3 = N+2
- 3 or 4 data blocks + 2 parity strips = 3/2 or 4/2
Overhead:
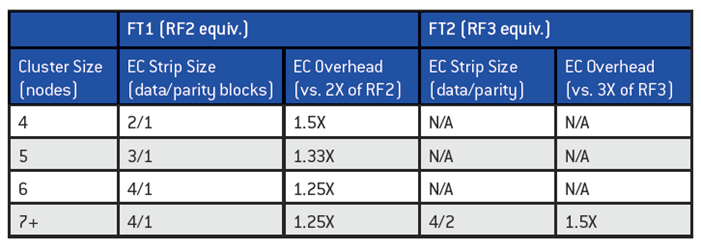
- Recommended to have cluster size which is at least 1 more node than combined strip size (data + parity)
- Allows for rebuilding in event of failure
- Ex. 4/1 strip would have 6 nodes
- Encoding is done post-process leveraging Curator MapReduce framework
- When Curator scan runs, it finds eligible extent groups to be encoded.
- Must be “write-cold” = haven’t been written to > 1 hour
- Tasks are distributed/throttled via Chronos
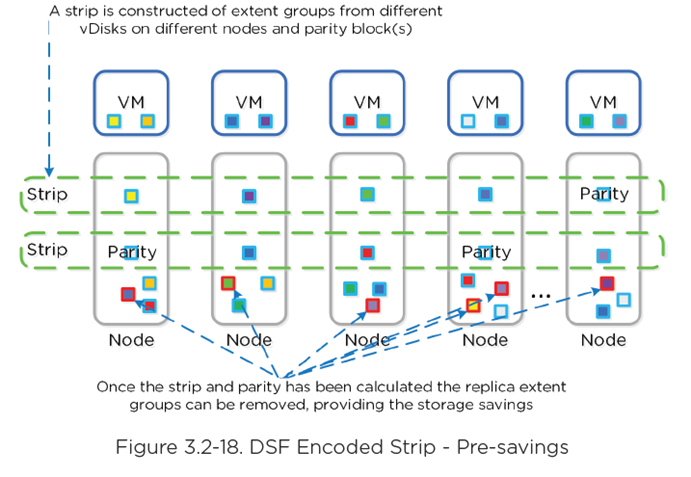
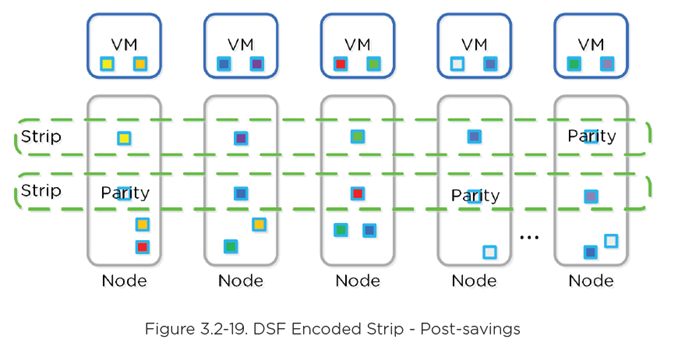
- EC pairs well with Inline Compression
Compression
Capacity Optimization Engineer (COE) performs data transformations to increase data efficiency on disk
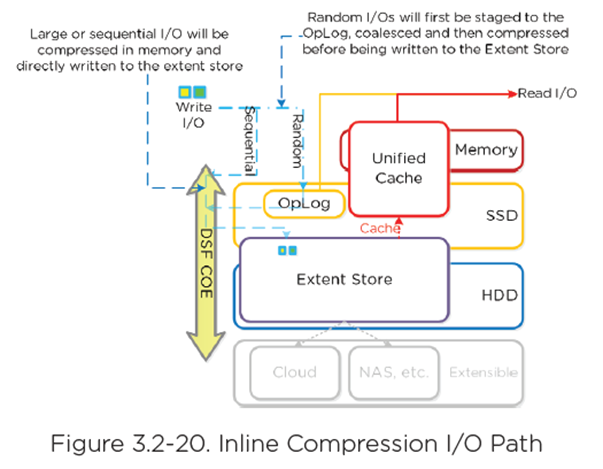
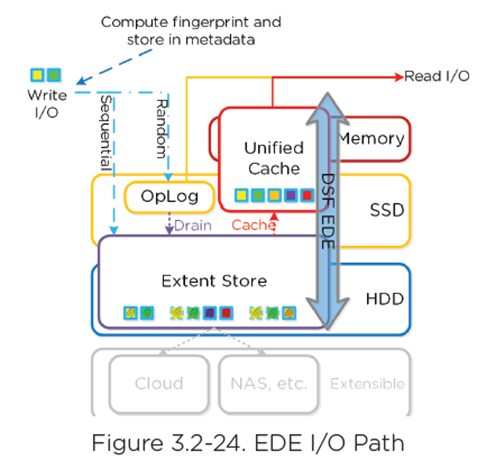
Inline
- Sequential streams of data or large I/O in memory before written to disk
- Random I/O’s are written uncompressed to OpLog, coalesced, and then compressed in memory before being written to Extent Store
- Leverages Google Snappy compression library
- For Inline Compression, set the Compression Delay to “0” in minutes.
Offline
- New write I/O written in uncompressed state following normal I/O path
- After compression delay is met, data = cold (migrated down to HDD tier via ILM) data can be compressed
- Leverages Curator MapReduce framework
- All nodes perform compression task
- Throttled by Chronos
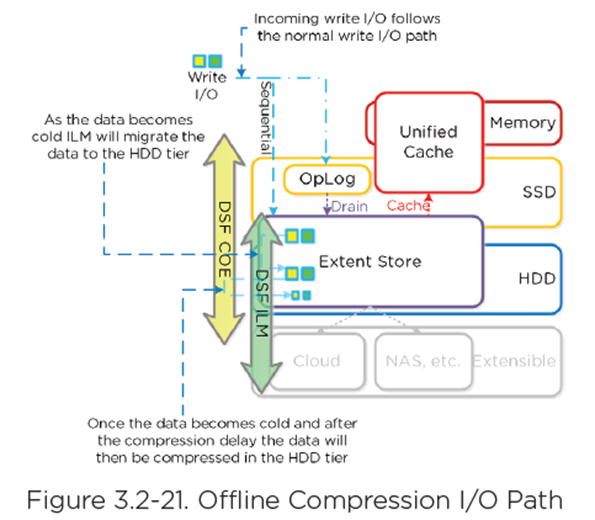
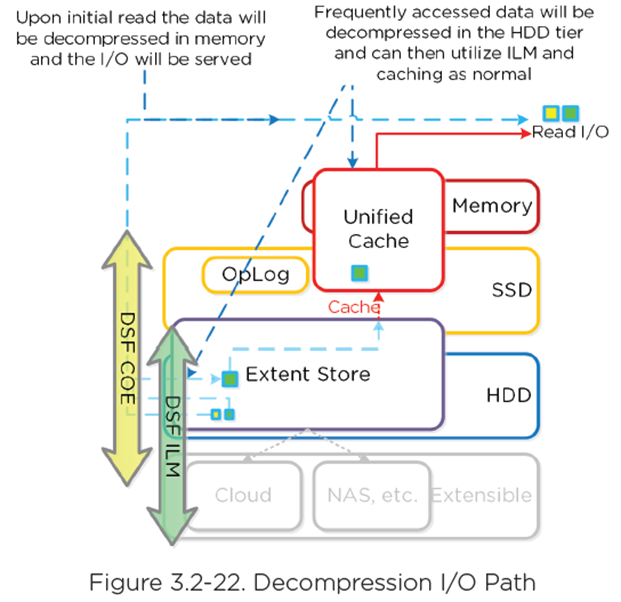
- For Read/IO, data is decompressed in memory and then I/O is served.
- Heavily accessed data is decompressed in HDD tier and leverages ILM to move up to SSD and/or cache
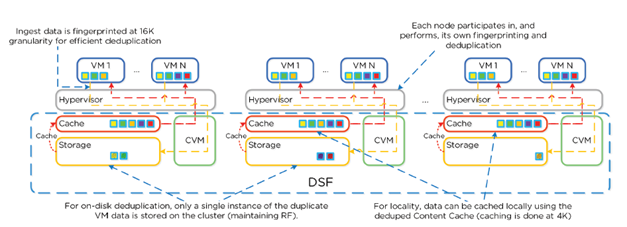
Elastic Dedupe Engine
- Allows for dedupe in capacity and performance tiers
- Streams of data are fingerprinted during ingest using SHA1 hash at 16k
- Stored persistently as part of blocks’ metadata
- Duplicate data that can be deduplicated isn’t scanned or re-read; dupe copies are just removed.
- Fingerprint refcounts are monitored to track dedupability
- Intel acceleration is leveraged for SHA1
- When not done on ingest, fingerprinting done as background process
- Where duplicates are found, background process removed data with DSF Map Reduce Framework (Curator)
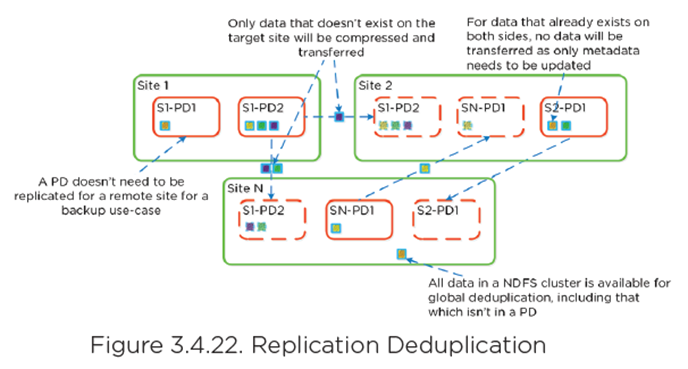
Global Deduplication
- DSF can dedupe by just updating metadata pointers
- Same concept in DR/Replication
- Before sending data over the wire, DSF queries remote site to check fingerprint(s) on target
- If nothing, data is compressed/sent to target
- If data exists, no data sent/metadata updated
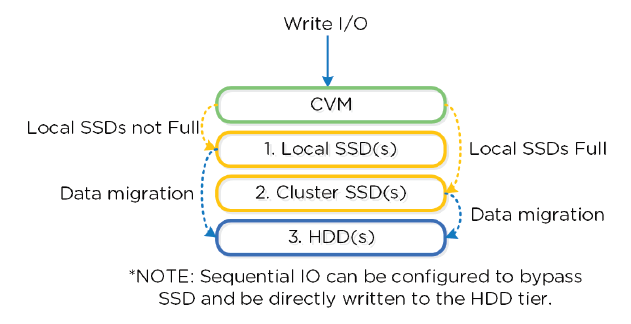
Storage Tiering + Prioritization
- ILM responsible for triggering data movement events
- Keeps hot data local DSF
- ILM constantly monitors I/O patterns and down/up migrates as necessary
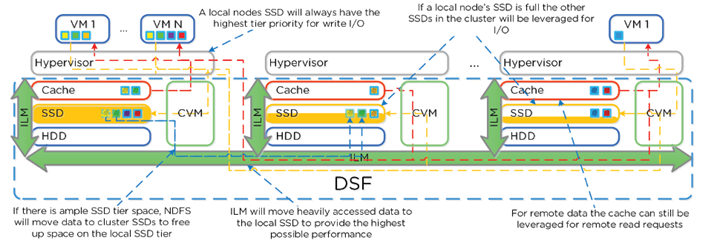
- Local node SSD = highest priority tier for all I/O
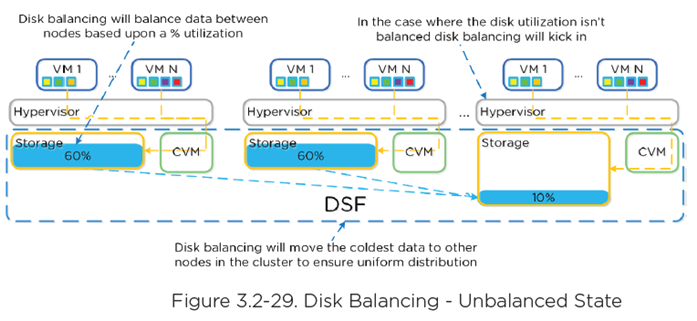
- When local SSD utilization is high, disk balancing kicks in to move coldest data on local SSD’s to other SSD’s in cluster
- All CVM’s + SSD’s are used for remote I/O to eliminate bottlenecks
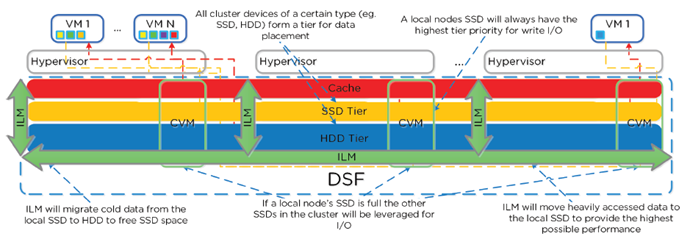
Data Locality
- VM data is served locally from CVM on local disks under CVM’s control
- When reading old data (after HA event for instance) I/O will forwarded by local CVM to remote CVM
- DSF will migrate data locally in the background
- Cache Locality: vDisk data stored in Unified Cache. Extents may be remote.
- Extent Locality: vDisk extents are on same node as VM.
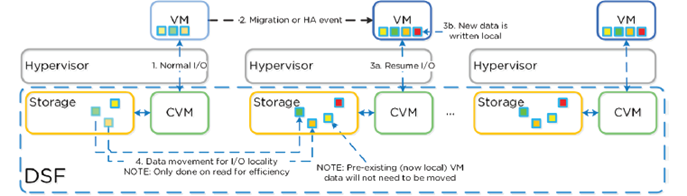
- Cache locality determined by vDisk ownership
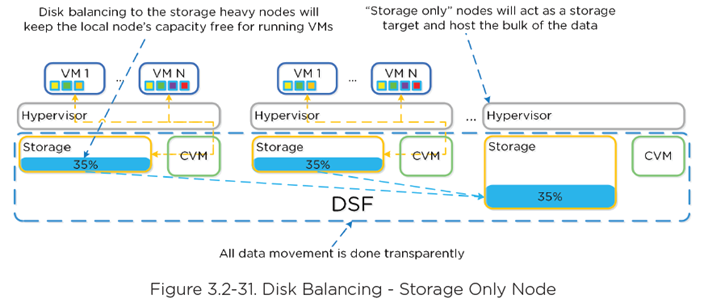
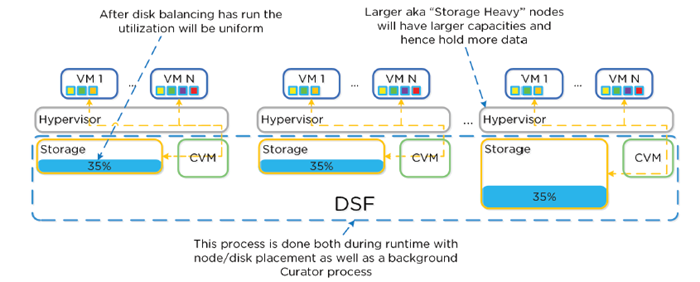
Disk Balancing
- Works on nodes utilization of local storage
- Integrated with DSF ILM
- Leverages Curator
- Scheduled process
- With “storage only” node, CVM can use nodes full memory to CVM for much larger read cache