Who’s the vSAN MASTER?

No, it’s not Sho Nuff. After configuring a new four-node vSAN cluster, we noticed some partition errors after a day or so of uptime. The strange thing was the cluster was divided into four partitions. Four masters, four partitions – that’s not good. Let’s see what the hosts have to say via the command line. I ran the following command on each node of the cluster:
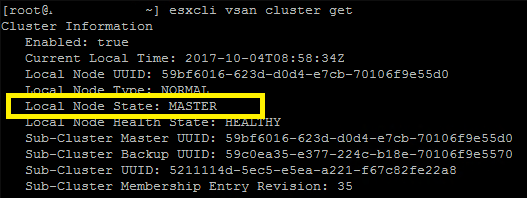
esxcli vsan cluster get
Surprisingly, each node shows “Local Node State” as “MASTER”. The “Sub-Cluster Member Count” is “1” for each node, and there are no member nodes. So what gives?
Break the Cluster
As this is a new cluster, I didn’t need to worry about breaking anything in Production. My first step was to leave the vSAN cluster on three of the four nodes, and then join them to the Sub-Cluster UUID of the remaining node. There is a good write up on manually configuring vSAN via esxcli here.
This does not work, as even after re-joining to the cluster each node still see itself as the MASTER. The next step was to leave the vSAN cluster manually, and then disable vSAN at the cluster level via the HTML5 client. vSAN is now disabled for the cluster, and can be verified with the same esxcli vsan cluster get command.
I re-enabled vSAN on the cluster via the HTML5 client, and the partition errors are gone! Problem fixed right? Only temporarily, as the partition errors resurface less than a day later. I opened a ticket with VMware, and the engineer noticed something very interesting.
Don’t Ignore vCenter
The advanced setting /VSAN/IgnoreClusterMemberListUpdates is set to “1”. The default is “0”, which means that once the vSAN cluster is created it should be managed by vCenter. Setting the flag to “1” essentially prevents vCenter from managing the vSAN cluster. We reconfigured this flag to “0” by running the following command on each of the member nodes:
esxcfg-advcfg -s 0 /VSAN/IgnoreClusterMemberListUpdates
We then proceeded to remove three of the four nodes from the vSAN cluster via the CLI, and re-join them to the Sub-Cluster UUID. Finally, we restarted the cmmdsd, and clomd services on the master node with the following commands:
/etc/init.d/clomd restart /etc/init.d/cmmdsd restart
And finally, just for fun we restarted the management services on the three remaining nodes. With that we now have a functional vSAN cluster with a single MASTER node. A quick retest of the vSAN Health validates that we now indeed only have one MASTER!